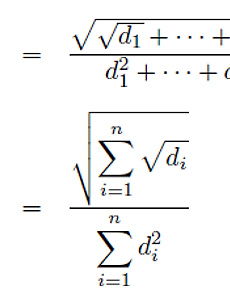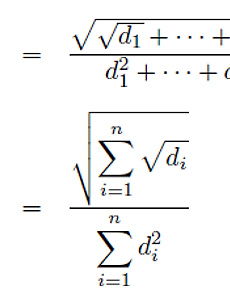 bootstrapping
본 글은 스크랩해온 글이다. resampling이란 모분포의 형태를 알 수 없을 때, 현재 갖고 있는 데이터의 일부분을 재추출하여 분포를 만든 후 관측하는 값의 통계적 의미를 확인하는 방법이다. 우선 estimator 에 대해 살펴 보고 넘어 가자. 일련의 데이터가 있을 때, 우리는 그 데이터의 총체적 특성을 나타내는 값으로 보통 '(산술)평균'을 이용한다. 즉, 평균이란 데이터 집합의 특성을 표현하기 위한 수치 중 하나의 예일 뿐이다. 최대, 최소, 중간값, 모드, 표준편차, skew, n-th moment 등 데이터 집합의 특성을 표현하기 위한 값에는 매우 많은 종류가 있다. 이 글에서는, 데이터가 주어지면 그 데이터를 이용하여 하나의 실수값을 계산해 낼 수 있을 때, 그 실수를 estimator 라..
2014. 2. 6.
bootstrapping
본 글은 스크랩해온 글이다. resampling이란 모분포의 형태를 알 수 없을 때, 현재 갖고 있는 데이터의 일부분을 재추출하여 분포를 만든 후 관측하는 값의 통계적 의미를 확인하는 방법이다. 우선 estimator 에 대해 살펴 보고 넘어 가자. 일련의 데이터가 있을 때, 우리는 그 데이터의 총체적 특성을 나타내는 값으로 보통 '(산술)평균'을 이용한다. 즉, 평균이란 데이터 집합의 특성을 표현하기 위한 수치 중 하나의 예일 뿐이다. 최대, 최소, 중간값, 모드, 표준편차, skew, n-th moment 등 데이터 집합의 특성을 표현하기 위한 값에는 매우 많은 종류가 있다. 이 글에서는, 데이터가 주어지면 그 데이터를 이용하여 하나의 실수값을 계산해 낼 수 있을 때, 그 실수를 estimator 라..
2014. 2. 6.