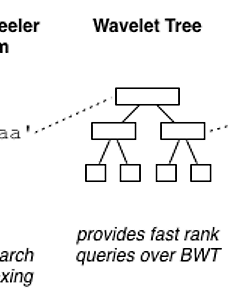
Bioinformatics/Algorithms34 버크하드-켈러 트리(Burkhard-Keller Tree) 본 분서는 http://blog.notdot.net/2007/4/Damn-Cool-Algorithms-Part-1-BK-Trees의 내용을 번역한 것이다. BK-트리, 또는 버크하드-켈러 트리는 트리 기반의 구조로 주어진 문자열에 대한 빠른 근사 매치를 하도록 해준다. 예를 들어, 스펠링 검사기나 '퍼지(유사어)' 검색을 수행하는 등의 작업에 사용된다. 더 자세히 예를 들자면, "aeek"를 검색하는데 이와 유사한 "seek"과 "peek"의 단어들이 반환되는 것이 목적이다. 무엇이 BK-트리를 빛나게 하냐면, 단순 무식한 무작위 검색 방식(brute-force search) 외에는 뾰족한 검색 방법이 없는 문제가 있을 때, 검색 속도를 엄청나게 향상시킬 수 있는 단순하고 우아한 방법을 제공해 주기 때문.. 2012. 11. 27. FM-Index와 역방향 검색(Backwards Search) 본 문서는 http://www.alexbowe.com/fm-indexes-and-backwards-search-32172의 내용을 편역 하였다. 또한, 위키피디아(http://en.wikipedia.org/wiki/FM-index)의 내용을 일부 번역하였다. BWT에 대한 내용은 다음글(http://juggernaut.tistory.com/entry/%EB%B2%84%EB%A1%9C%EC%9A%B0%EC%A6%88%ED%9C%A0%EB%9F%AC-%EB%B3%80%ED%99%98BWT-BurrowsWheeler-transform)을 참고하기 바란다. FM-색인 FM 색인은 문자열에 대해서 BWT를 수행함으로써 얻어질 수 있다. BWT를 수행하게 되면, 행렬의 열은 기본적으로 정렬된 문자열의 접미사가 되고.. 2012. 11. 24. 버로우즈-휠러 변환(BWT, Burrows-Wheeler transform) 이 변환은 블록 정렬 압축으로 불리지만, 실제로는 데이터를 압축하지는 않고 변환만 수행한다. Michael Burrows 씨와 David Wheeler 씨가 켈리포니아의 DEC System Research Center에서 일하면서 고안한 것이다. 이 변환을 수행하게 되면 같은 문자들이 묶여서 반복되는 양상의 문자열이 생성된다. 마찬가지로 데이터의 크기를 줄이지 않지만 비슷한 의미를 가진 전향(MTF, Move To Front) 변환 등과 함께 사용되고 최종적으로는 반복 길이 부호화 인코딩(RLE, Run Length Encoding)과 같은 알고리즘을 이용하여 데이터를 압축하는데 사용되기도 한다. 큰 상관은 없는 이야기이지만, 문자열을 전향 변환으로 처리하는 과정에서 데이터의 반복이 지역적 상관도를 가지.. 2012. 11. 22. 접미사 배열(Suffix Array) 접미사 배열은 접미사 트리의 공간 소모량을 줄이기 위해 고안된 데이터 구조이다. 이 데이터 구조는 아리조나 대학의 Udi Manber 씨와 Gene Myers 씨에 의해서 1989년 5월에 제안되었다.다음은 해당 논문의 연결이다.http://www.google.co.kr/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&ved=0CC8QFjAA&url=http%3A%2F%2Fwebglimpse.net%2Fpubs%2Fsuffix.pdf&ei=5vytUPW1DsK1tAa214HYDA&usg=AFQjCNFj4JQQ2S1vdKZ09py7_SLZ45m_SA&sig2=b_RSaBtaOhl2V_yGzA2gHw 이 데이터 구조는 기본적으로 다음과 같이 생성된다.주어진 문자열에 대.. 2012. 11. 22. 이전 1 ··· 5 6 7 8 9 다음